'Contents based filtering'은 콘텐츠에 대한 분석을 기반으로 추천하는 방식입니다. 사용자가 특정 아이템을 선호하는 경우 그 아이템과 비슷한 콘텐츠를 가진 다른 아이템을 추천해줍니다. 영화 콘텐츠의 경우라면 스토리나 등장인물, 감독을, 상품이라면 상세 페이지의 상품 설명을 분석합니다. 예를 들어 사용자 A가 Item A에 굉장히 높은 평점을 주었는데 그 Item A가 액션 영화이며 B 감독의 작품이라면 B 감독의 다른 액션 영화를 추천해주는 것입니다. 굉장히 단순한 아이디어로 과거에 사용했으나 현재는 잘 사용하지 않는 방법입니다.
이 Contents-based filtering은 CF의 한계를 일부 보완해줄 수 있습니다. 아무런 정보가 없는 유저에게 여러 상품을 무작위로 노출시킨다음, 반응을 보이는 상품과 유사하게 묶인 상품들을 노출시키는 방법을 택하는 것입니다. 즉 많은 양의 사용자 행동 정보가 필요하지 않아 Cold start problem 문제를 보완할 수 있다는 것입니다. 이는 아이템과 사용자 간의 행동을 분석하는 것이 아니라 콘텐츠 자체를 분석하기 때문입니다. 간혹 컨텐츠 필터가 오작동하면 유저 데이터가 오염되어서 초기 데이터의 오류를 수정하는데 오랜 learning이 필요한 경우가 있습니다. 또, 최초 방문시에 컨텐츠 필터가 잘 작동하더라도, 협력 필터로 특정 상품에 쏠린 데이터가 증가하면서 결국 positive feedback problem을 극복하지 못한 사례도 많았습니다.
콘텐츠를 분석하고 분류하는 작업은 기계가 할 수도, 사람이 할 수도 있습니다. 한 예로 넷플릭스에 올라오는 콘텐츠의 분류 방식을 들 수 있습니다. 넷플릭스에 올라오는 콘텐츠는 50개의 태거(Tagger)에 의해 분류됩니다. 이들의 역할은 콘텐츠를 면밀하게 보고 여기에 태그를 다는 것입니다. 태거 덕분에 넷플릭스는 사용자에게 더욱 정교한 추천을 할 수 있습니다. 사람이 단 태그를 바탕으로 콘텐츠를 5만 종으로 나눠 정리하기 때문입니다.
인터넷 신문사에서는 주로 이 업무를 기계가 실행합니다. 이때 사용되는 기술은 텍스트 마이닝 기술입니다. 매일같이 아이돌 그룹 B의 기사를 찾아보는 가상의 팬 C 군이 있다고 가정해보겠습니다. 신문사는 텍스트 마이닝으로 C 군이 읽는 기사 텍스트를 분석하고 이와 관련 있는 또 다른 B 기사를 C 군에게 추천합니다.
물론 이 방법에도 문제점이 존재합니다. 가장 큰 문제로 꼽히는 것은 '메타 정보의 한정성'입니다. 상품의 프로파일을 모두 함축하는 데에 한계가 있다는 점입니다.
쉬운 설명을 위해 아이돌 그룹 B의 또 다른 팬 T군이 있다고 가정해보겠습니다. T군은 그룹 중에서도 한 멤버를 좋아하며 그와 관련 있는 기사를 주로 찾아보았습니다. 하지만 기사 내용만으로 콘텐츠를 분류해야하는 신문사 알고리즘 입장에서는 T군의 성향을 세부적으로 파악하기가 어렵습니다. 그룹 B 전체의 기사 텍스트와 그룹 B 중 한 명의 멤버에 대한 기사 텍스트에서 큰 차이가 없기 때문입니다. 여기서 콘텐츠 기반 필터링의 정밀성이 떨어지는 문제가 발생합니다.
* 텍스트 마이닝 기법
가장 흔한 방법은 TF-IDF를 활용하는 방법입니다.
1. stop word를 제거합니다. 자연어 문장 내에서 많이 쓰이지만 전혀 키워드로 쓸모없는, 영어의 The, is 등과 같은 단어이고, 한국어에서는 이, 그 등과 같은 단어가 해당될 것입니다.
2. 이어서, TF-IDF를 계산합니다. TF-IDF(Term Frequency – Inverse Document Frequency)는 여러 문서의 집합에서 어떤 단어가 어떤 문서에서 얼마나 중요한지를 나타내 주는 식입니다. TF는 한 문서 내에서 어떤 단어가 나타나는 빈도이고, IDF는 어떤 단어가 나타나는 문서 빈도의 역수를 가리킵니다. TF와 IDF값을 곱해 TF-IDF값을 얻어냅니다.
3. 적절한 Threshold 값을 주고 이 이상의 TF-IDF 값을 갖는 단어를 뽑아 냅니다.
* 문서간 유사성 계산하기
몇가지 계산법이 있는데 대표적으로 자카드 거리(Jaccard distance)를 계산하거나, 코사인 거리(Cosine distance)를 계산할 수 있습니다.
1. 자카드 거리는 자카드 인덱스 J(A, B)를 구한 뒤, 전체 집합 1에서 빼는 방법입니다.


2. 코사인 거리는 단어의 집합으로 표현된 문서를, 집합이 아니라 벡터로 간주하고 벡터상 거리를 구하는 방법입니다. 코사인 내적을 구하는 식에서 코사인 유사도 similarity를 구한 뒤 마찬가지로 전체 집합 1에서 빼게 됩니다.

*아이템 프로파일(벡터)의 표현
아이템별 특성-값의 쌍으로 구성되는 벡터를 만드는 과정입니다. 공급자나 제작자로부터 얻어서 쉽게 얻는 정보나 문서로부터 높은 TF-IDF값을 같는 키워드들이 등장하는 벡터를 구성할 수 있습니다.
예를 들어 각각 5명의 배우가 출연하는 A와 B영화를 가정해 봅시다. 만약 2명의 배우가 A와 B 모두에 출연했다면 영화배우의 수는 a, b, c, d, e, f, g, h로 8명일 것입니다. 이럴경우

이렇게 아이템 프로파일을 구성할 수 있습니다. b와 f 배우가 두 영화 모두에 등장하는 것을 알 수 있습니다. 한편, 각 영화에 3점, 4점이라는 평점이 있다고 가정할 수도 있습니다. 그런 경우엔

위와 같이 ‘스케일링 팩터’를 이용하면 됩니다. 0과 1이 대부분인 벡터에서 3과 4가 그값 그대로 작용된다면, 코사인값을 계산할 때 평점이 배우에 대한 점수보다 훨씬 중요하게 작용하게 되므로 조절하는 것입니다.
위 벡터 A와 B에 대한 코사인 값을 구해보겠습니다. 위에서 similarity로 제시된 식에 따르면
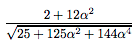
이렇게 주어지고,위 값은 코사인 값으로 값의 범위는 -1에서 1이며, 알파 값에 따라 아주 다른 값이 등장하게 됩니다.
'Team Project > 국내어디가' 카테고리의 다른 글
| 스터디1-Collaborative Filtering(협업필터링) (0) | 2020.02.28 |
|---|---|
| 프로젝트 방향성 회의 내용 (0) | 2020.02.28 |
| 191119~191201 새로운 주제 (0) | 2019.11.25 |
| 191029 ~ 191118 주제 변경 이유, 새로운 주제 (0) | 2019.11.25 |
| 191008~191028 인공지능 공부 (0) | 2019.10.28 |
댓글